Hello
I have an Event Processor (pooled streaming) that is busy with a quite long replay. In the logs I see in a quite regular pattern that the event stream gets closed (“AxonServerException: The Event Stream has been closed, so no further events can be retrieved”) approximately every 5 minutes. As a result, the event processor is switched to another processor.
As the event processor has to handle some events that may take a bit longer, I tried out the “enableCoordinatorClaimExtension” setting of the PooledStreamingEventProcessor that I found in the JavaDoc. I am not sure if this is an official feature as it is not documented anywhere, but it seemed to help with token stealing problems. Now I am wondering if this setting could be causing the processor to switch every 5 minutes.
That’s…problematic, @klauss42! Do you perhaps have a longer stack trace for the AxonServerException you’re seeing? On face value I would not expect this to happen periodically at all.
This setting is an optimization on the PSEP that ensures a given application instance running your PSEP will extend token claims while event handling is taken place. In other words, it is intended to minimize token stealing between instance when event handling tasks take long. If anything, I’d keep it on in your environment, at least for the event handling components that may take a long time to process.
Furthermore, I don’t assume it to be the culprit for the exceptions you’re receiving.
org.axonframework.axonserver.connector.AxonServerException: The Event Stream has been closed, so no further events can be retrieved
at org.axonframework.axonserver.connector.event.axon.EventBuffer.peekNullable(EventBuffer.java:177)
at org.axonframework.axonserver.connector.event.axon.EventBuffer.peek(EventBuffer.java:136)
at org.axonframework.eventhandling.pooled.Coordinator$CoordinationTask.eventsEqualingLastScheduledToken(Coordinator.java:1025)
at org.axonframework.eventhandling.pooled.Coordinator$CoordinationTask.coordinateWorkPackages(Coordinator.java:999)
at org.axonframework.eventhandling.pooled.Coordinator$CoordinationTask.run(Coordinator.java:818)
at org.axonframework.eventhandling.pooled.Coordinator$CoordinationTask.lambda$scheduleCoordinationTask$23(Coordinator.java:1068)
at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:572)
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:317)
at java.base/java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:304)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1144)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:642)
at java.base/java.lang.Thread.run(Thread.java:1583)
Caused by: io.grpc.StatusRuntimeException: UNKNOWN
at io.grpc.Status.asRuntimeException(Status.java:532)
at io.grpc.stub.ClientCalls$StreamObserverToCallListenerAdapter.onClose(ClientCalls.java:481)
at io.grpc.PartialForwardingClientCallListener.onClose(PartialForwardingClientCallListener.java:39)
at io.grpc.ForwardingClientCallListener.onClose(ForwardingClientCallListener.java:23)
at io.grpc.ForwardingClientCallListener$SimpleForwardingClientCallListener.onClose(ForwardingClientCallListener.java:40)
at io.grpc.internal.ClientCallImpl.closeObserver(ClientCallImpl.java:564)
at io.grpc.internal.ClientCallImpl.access$100(ClientCallImpl.java:72)
at io.grpc.internal.ClientCallImpl$ClientStreamListenerImpl$1StreamClosed.runInternal(ClientCallImpl.java:729)
at io.grpc.internal.ClientCallImpl$ClientStreamListenerImpl$1StreamClosed.runInContext(ClientCallImpl.java:710)
at io.grpc.internal.ContextRunnable.run(ContextRunnable.java:37)
at io.grpc.internal.SerializingExecutor.run(SerializingExecutor.java:133)
... 3 common frames omitted
Thanks for sharing that, @klauss42. Sadly, the UKNOWN message coming from gRPC does not help at all, as you may have guessed.
In your first message, you stated that it happens every 5 minutes. Is that an approximation, or exact? If the latter, we have a detail to search for in I assume gRPC settings.
Hi Steven,
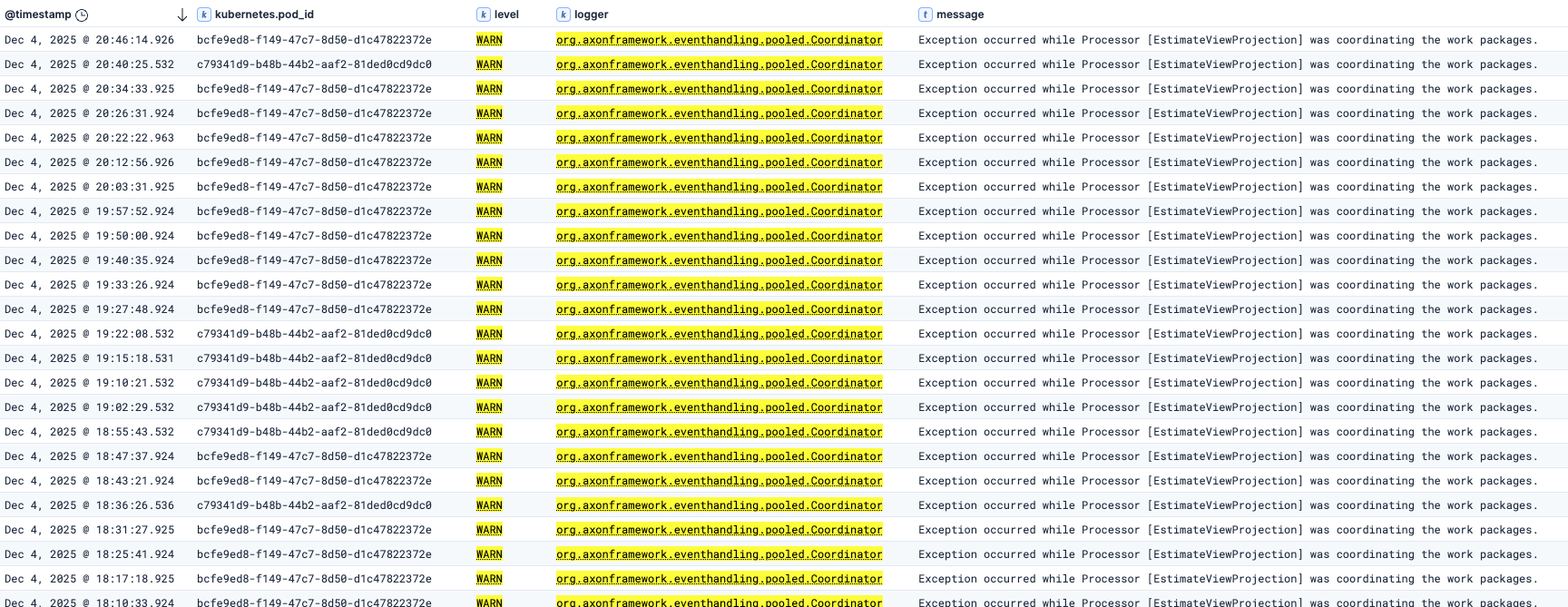
the 5 minutes is an approximation, it a range of roughly 5 minutes. See a screenshot from our logs foltered for the event stream closed messages:
We only see these recurring warnings with the one event processor that is performing a long replay. With the other event processors, there are occasional token steals, but not in this recurring pattern.