CASE:
We had some faulty data in events and resolved this by upcasting the event based on information in other events. so we handle two events in an upcaster, from one type of event we take data, and we put it in the other event to fix the data.
I know that this is statefull, and that problems arrise when not the whole event stream is replayed at once. We are however getting problems with the event processors upon replay. When an event processor doesn’t have a handler for an event it doesnt get send through the upcaster chain e.g not handled at all and is filtered out of the stream. I understand that this is for performance reasons?
Question 1:
Is there a way to force a replay or a tracking event processor to send all events through the upcaster chain even when there are no handlers present, or are there other solutions that we should go for?
Question 2:
Did we take the wrong approach for this case? Would it have been better to apply a new event but then with correct data overwriting the faulty event? But how would event order play into this for projections?
@Gerard Thanks for checking out my post. I saw you moved it under Axon Server, I justed wanted to let you know we don’t use axon server for our storage. So it might not be the right tag/location now
Moved it back, I thought the optimization was only implemented for Axon Server, that’s why I moved it. It would help to know what you use as an event store. The way to work around the optimization is to add a handler for the event you need for upcasting.
We use JPA with an sql DB currently… (but that’s a topic for another time )
We have that workaround implementend at the moment, but it seems very off to use for the long term. Its very implicit and confusing in the code. And the projection and upcaster are now coupled by behaviour. Also the upcaster wont automatically work for other processors without duplication of the workaround.
Is there any other way we can force the events to be passed through the upcaster chain? Or can we add handlers to the upcaster itself?
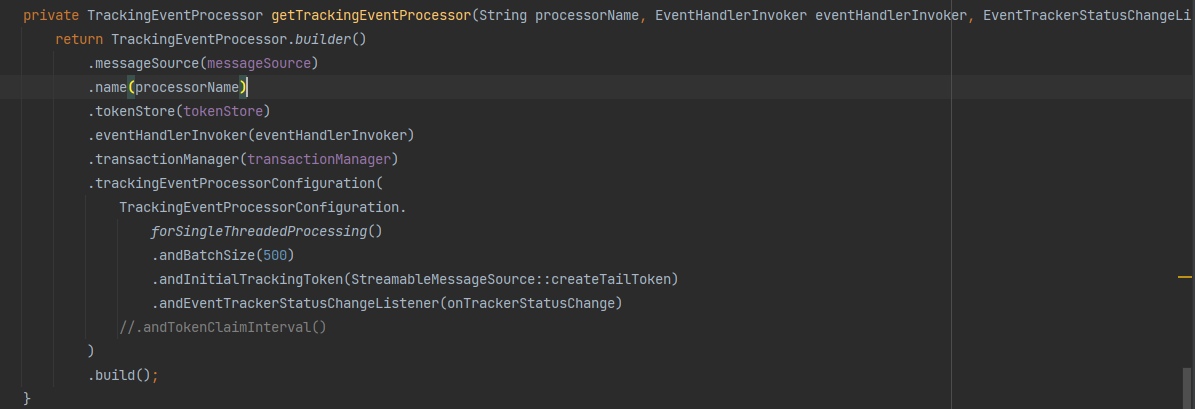
We use the replay API and manualy create a TrackingEventProcessor for starting the replays, so we have access to all settings I believe
Wouldn’t that go against the fundamentals of event sourcing and bring the risk of data corruption when human errors are being made?
As well as a lack of tools in the long term for versioning events? E.g splitting events in two for example, where the source event is possibly not handled by the processing group?
Although im all up for copy and transform migrations as described here, but if possible with the help of upcasters?
It should indeed be the last resort. And you want to properly test using a copy of production before doing so on the production. But it seems having a stateful upcaster, together with the need to consume certain events to get it right, might be last resort enough.
I’m not sure we have anything out of the box, but you could use an event processor, with all the upcasters, and read all the events from database/table x, and writhe them to another? Having no downtime and consistency will be tricky.