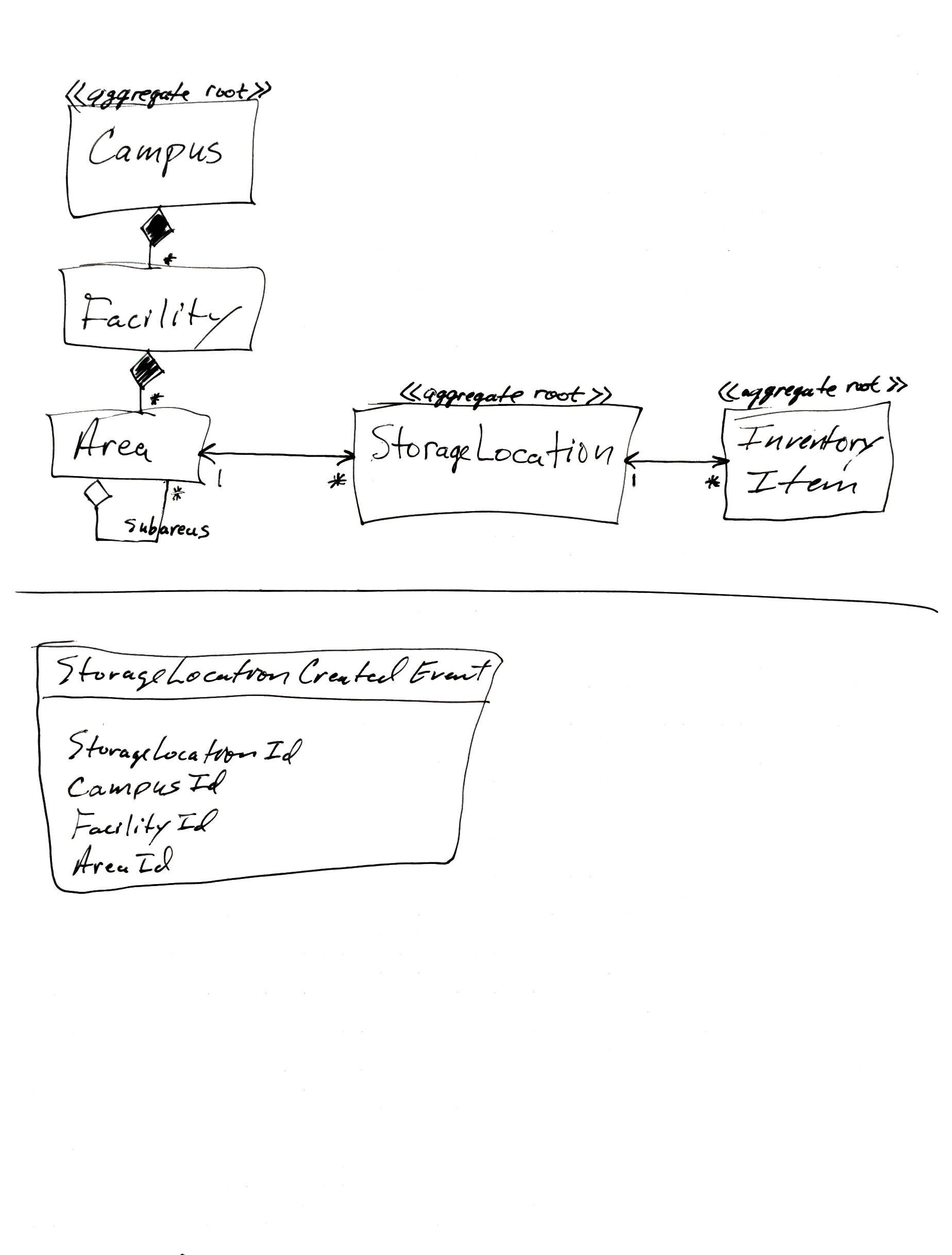
I have a question about best practices. See the attached class diagram where I show a simple model of geographically distributed warehouses (decomposed into areas within facilities within campuses) with storage locations where inventory items are stored.
My questions is as it relates to responding to the event that is raised upon storage location creation: StorageLocationCreatedEvent.
In order to materialize the view as shown, a query side event listener (StorageLocationUpdater) will listen for StorageLocationCreatedEvent and will save a new StorageLocation query component. So far so good. But now, is where I have a question. Should I lookup the corresponding Campus.Facility.Area query components from this StorageLocationUpdater, record the StorageLocation reference in the Area and save the Campus? Or should I create StorageLocationCreatedSaga that starts on a StorageLocationCreatedEvent and sends commands to the Campus aggregate in order to record the new storage location in the area.
With the second approach I would then need to implement a Campus/Area query side updater that will respond to the events from the Campus aggregate indicating the area has a new storage location. It seems like both ways will work, should I have a preference for one approach over the other?
Upon thinking some more about this, I guess it really comes down to whether or not there are any business concerns of the campus related to a storage location being added. If there are none then it's simplest to let the view logic manage the campus side of the view when updating the storage location view...
I suppose the StorageLocationCreatedEvent contains a reference to the Area in which the location was created? The query model shouldn’t need to query anything for this reference, as it would already be contained in the event itself.
This doesn’t seem like a problem that needs a Saga, as there doesn’t seem to be any coordination of activities. All I discover here are just events of areas and subareas being created based on which a view model is created.
Does that make sense?
That does help. To be clear, if there were coordinating activities required on the campus side when a new Storage Location is created–like if there were some sort of facilities approval or other workflow triggered by the addition of new storage locations–then a cross context saga that responds to a warehousing StorageLocationCreated event by issuing a facilities AddStorageLocationId command…
At the heart of this question lies my struggle to understand how to approach this problem both from a DDD bounded context and CQRS perspectives.
As it exists presently, my application is comprised of following bounded contexts:
Facilities Commands (a jar module) – commands that enable the creation of campus, facility and area instances
Warehousing Commands (a jar module) – commands that enable the creation of storage locations an inventory items
Package Detail Commands (a jar module) – commands that enable the creation of detailed accountings of instances of physical packages…the intent is that a package will be tracked as an inventory item, which requires a cross context saga to manage
Combined View/Query Side Monolith (a spring boot deployment) – (above) command modules plus other modules that implement cross context sagas and event listeners (view updaters).
With this structure there are no hard dependencies between any of the first 3 contexts (facilities, warehousing, package details). There are some conceptual dependencies but no dependencies that result in runtime coupling. The fourth context however (the monolithic application) has dependencies on all of the other contexts–it’s like the glue between them.
Does this seem reasonable and/or “on track”?
Thanks for your time considering this! I know it must be hard to fill in all the blanks on a question like this.
this does seem to make sense. In general, I try to put command “components” into separate jars, just like you did, but then do the same for the query component(s). Then, additionally, I would have 1 more jar that contains the bootstrap (e.g. Spring Boot Application class) and has a dependency to all modules that I want to include. This way, creating an additional deployable that contains only 1 (or a few) of the components is very easy.
Late follow-up question on jars/module: do you put your aggregate root definitions in different jars than the commands and events so that “clients” can just import the command and event definitions without importing any of the capability side?
Late follow-up question to to be sure I’m tracking with you because this is the granularity I was thinking as well but want to get the separation correct before making a bunch of maven modules
If we have separate client processes sending commands or queries over distributed bus (for location independence) then would your jars look something like this (assuming the agg type is “acct”:
acct-cmd-api.jar - Commands and events only
acct-cmd-svc.jar - Aggregate root - depends on acct-client-api for command and event definitions
acct-cmd-server.jar - spring boot jar that depends on acct-cmd-svc.jar (and transitively acct-cmd-api.jar)
acct-query-api.jar - For use by clients that only need to query, contains queries and return data types
acct-query-svc.jar - Contains the implementation of the query service, depends on acct-query-api.jar
acct-query-server.jar - spring boot jar that depends on acct-query-svc.jar and transitively acct-query-api.jar
yes, that’s exactly the separation/modularization that we recommend.
Beware with naming though. There is no such thing as ‘the’ query module. There will likely be multiple, separated based on audience or query method.