Greetings to everyone and let me start by saying how much I appreciate the dedication and community-centered approach of this framework’s team! Kudos to you guys!
A little background: I have been responsible for researching and deploying microservice-migration solutions for our development team, as the next milestone for us is to migrate existing monolithic suite of applications to an new microservice ecosystem. I have been familiarizing myself with the Axon Framework, Spring Cloud extension and Spring AMQP extension for the past few months and it has been a successful discovery in our team. It has been agreed that Axon will be the main framework for the above mentioned migration process!
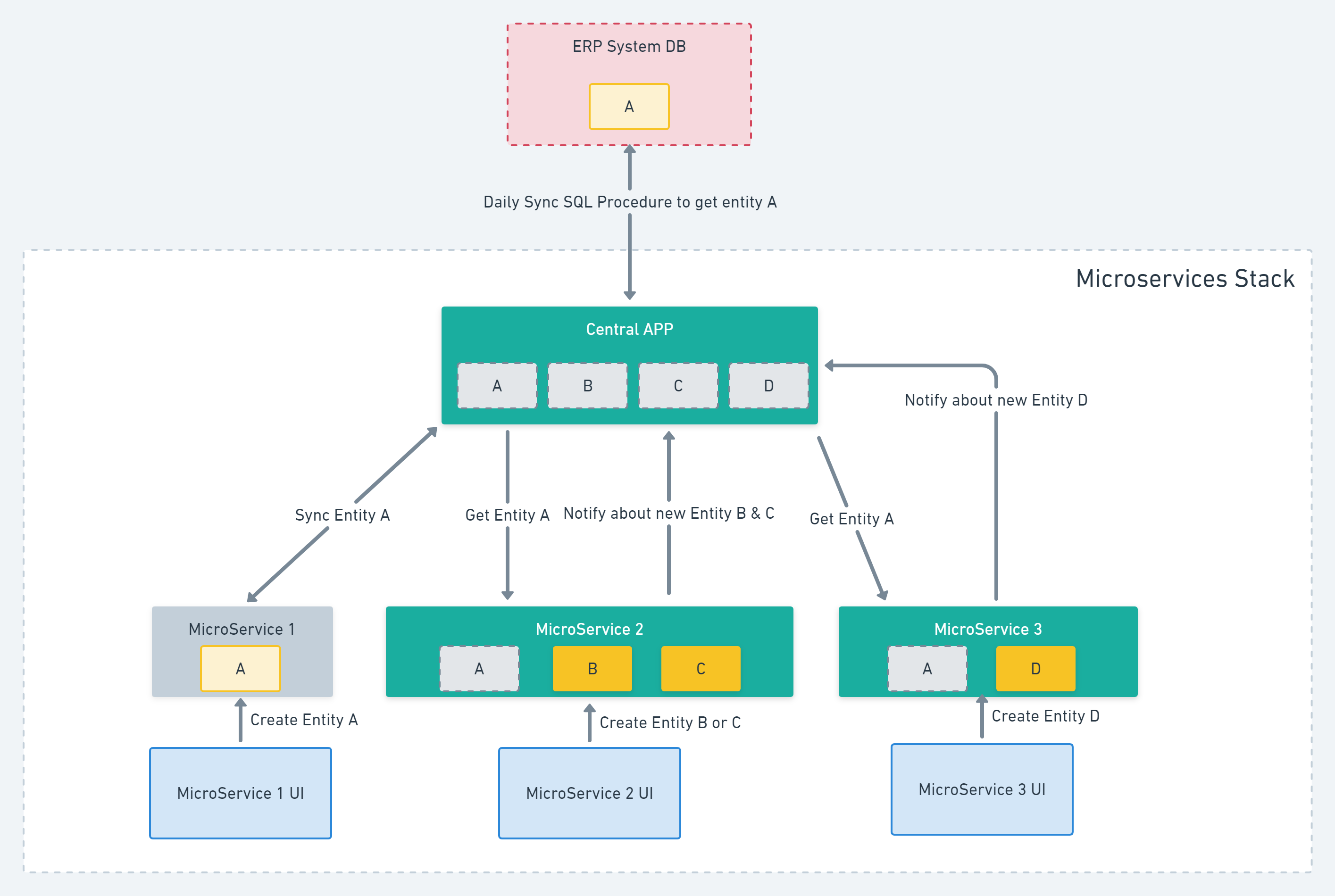
After migrating one of the monoliths successfully, I’ve come across a different challenge that I would love to receive input on. The microservice system will have one main ‘central’ application in that this one service will be responsible for integrating with an ERP and act as our own data warehouse. This will replace the current approach in which each application directly integrates with the ERP. As an effect of the periodic data synchronization between Central-App and the ERP, all microservices should be informed to start a synchronization of data received by the Central App.
-
The first thought I had in mind was to send an individual command from within a Saga, for each Microservice, during the syncing, i.e. App1SyncClientCommand, App2SyncClientCommand, and so on. The main problem here I believe would be the amount of overwhelming amount of commands as there will be one for each client for each application.
-
The second approach i have thought of would be a PULL approach, that is after a Client’s data has been synchronized centrally, an Event will be dispatched to all microservices, making them aware that there is new data to be synced locally. In turn, each microservice could send some sort of PULL command for an Aggregate, or even an Event that would let the Saga know, there is a new Subscriber that needs the newly synced data.
That would be my main concern, but I would also be curious about another design aspect: The ClientAggregate is present inside each of the microservices. Is there possible, and if so would you encourage, having this common Aggregate inside something like a shared-module to be visible for each microservice or will it be better to have a separate implementation?
Thanks for your attention!