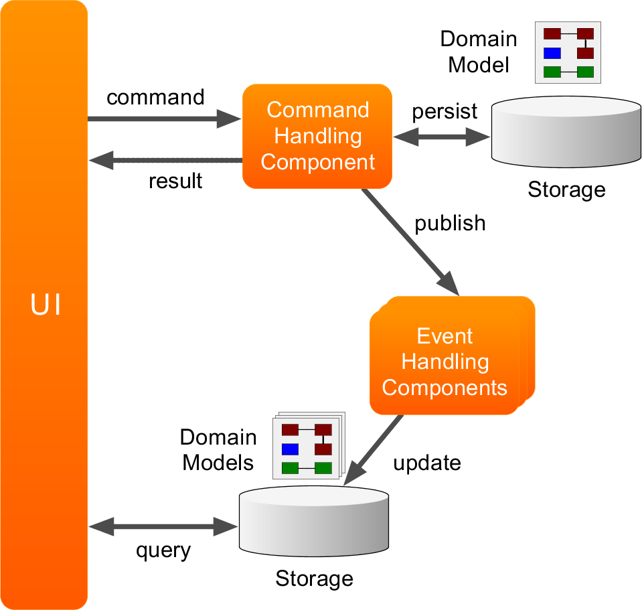
So do we save command model before publishing an event or we should publish an event first and then create command model from those events. I look at the Aggregate structure and it seems to be the second option since aggregate retrieve state from event handler, but from the image it seems to be the first option. which one is correct or neither?
@CommandHandler
public void handle(TestCommand cmd) {
AggregateLifecycle.apply(event)
}
@EventSourcingHandler
public void on(TestEvent event) {
// so command model was created after publishing an event?
this.state = event.state
}
There is truth in both statements, and it depends on the configuration of your application. Axon Framework supports two ways of saving the command model: Event-Sourced and State-sourced. Let’s compare the two.
Event sourced
When a command is sent to an aggregate, the state of the aggregate is rebuilt out of the events, hence it is Event-Sourced. The events are played in order on the aggregate, using @EventSourcingHandler methods for this. If there is no handler, the event is ignored.
The command handler can then publish new events, that will be stored in the event store when the transaction succeeds. This is the updating of the command model part of the diagram.
The event handlers subscribed to those events will be executed either during that same transaction at the moment the event is published (subscribing event processor), or after the transaction in an eventual consistent fashion (streaming event processor).
State sourced
State-Sourced aggregates are almost the same as Event-Sourced. But instead of loading the aggregate by replaying the events on it, the entire model is saved as an Entity in the database. The aggregate can be configured with JPA to do this. In a sense, updating the command model has changed from saving the events to saving the mode state.
Which one is better?
Event-Sourced aggregates have the benefit that they are easier to change. Changing the data structure is always possible to suit your needs. With State-Sourced aggregates you will have to migrate your database model in that case. In additions, mistakes of the past are harder to correct when the aggregate is State-Sourced.
Larger aggregates need to be snapshotted, since loading all events for every command will incur a performance penalty. By saving the model state every 20 events or so (this is configurable) you save a lot on performance.
I hope this gives you enough information about how the CQRS pattern works with Axon Framework aggregates. If there are any other questions, let me know!
Thank you the information. So for the Event sourced approach, does it have some kind of eventual-consistency problem since the state is created from the previous events. Let’s say I have two commands, suppose these two command are sent to the aggregate at the same time. Would this caused race condition or AxonFramework handles each command in sequence.
If there were no measures taken, that would definitely be a problem!
Axon Server actually makes sure that all commands for the same aggregate are queued and always are directed to the same application node. This also allows for caching optimizations.
If you are running on a database (e.g. Postgres), you should have a unique contract on (AGGREGATE_ID, SEQUENCE_NUMBER) to prevent two commands from publishing at the same time (same index).
One of these commands will roll back on a unique constraint error and can be retried. The Axon server approach works more gracefully.