We have encountered a situation that causes the Axon GapAwareTrackingToken to fail to advance and process new events. It’s worth noting that we did not face this problem when using Axon Framework version 4.5.15, Spring Boot 2.7, and XStream as serialization.
Expected Behavior:
The tracking processors should advance as usual and process new events.
Actual Behavior:
New events are not being processed.
Workaround:
Restarting the services resolves the issue.
Questions
Are there any differences in the behavior of GapAwareTrackingToken between Axon Framework v4.5.15 and v4.9.0 that could explain the issue?
Are there any known issues or bugs in Axon Framework v4.9.0 related to event processing?
Could there be any compatibility issues between Axon Framework v4.9.0 and other components in the system, such as Spring Boot 3.2.1 or PostgreSQL version 13?
How does the use of Jackson serialization compare to XStream serialization in terms of compatibility and performance with Axon Framework v4.9.0?
Are there any specific error messages or logs indicating why the new events are not being processed?
Can you maybe try is version 4.9.3 of framework and/or bom version 4.9.4 solves the problem? Recent changes were making it need less memory, which introduced a bug, which has been fixed in the latest.
Thank you for your reply. We actually first encountered the problem with Axon v4.9.3, and then based on the feedback provided on the GitHub issue, we downgraded to version 4.9.0.
It’s hard to say in that case. Maybe the load has increased and/or because there are already a lot of events, things are being slowed down to a point the gaps become too big?
I don’t think our system is under a heavy load, I believe ~90,000 events is a small number, and we haven’t changed anything in our infrastructure recently.
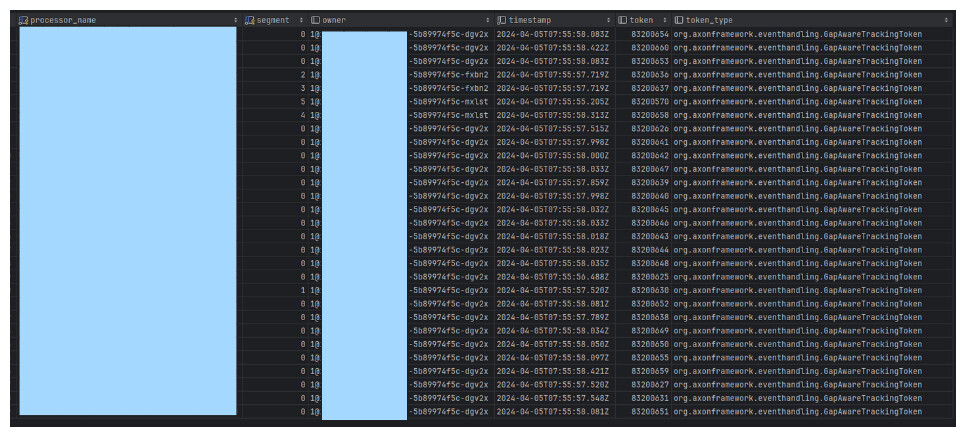
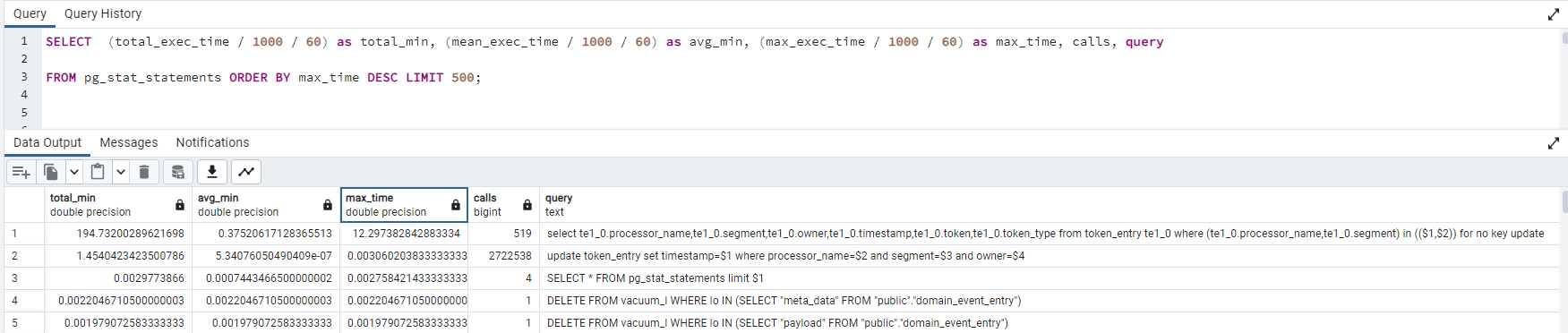
We’ve enabled pg_stat_statements for PostgreSQL to gain deeper insights into our application’s behavior; we found out that select queries on the token entry table are time-consuming, averaging ~200 minutes for 519 calls.
I would advise to keep 4.9.3, as that also solved the issue for the screenshotted mmaask. Only they used the bom, so where actually first using 4.9.2 instead of 4.9.3. If the issue persists, please open an issue on GitHub. What is a large number also depends on the hardware, and the size of the events. With so many changes it’s hard to pin it down.
Maybe it’s another problem entirely? Do you see any errors from the event processors that stopped?
Yes, I agree; you’re correct about the load on the system, but I don’t think that’s the case because before updating the service we reached millions of events in the database and the service was working normally.
We enabled debug logs for Axon, no errors have been detected from the event processors. Today for example, we attempted to launch a process (we call it a dry run job). The command intended to create the aggregate is CreateDryRunJobCmd. This command is expected to publish a DryRunJobCreatedEvent, which was indeed persisted in the domain event entry. However, this event was not handled by any event handlers (saga or projection).
I’ve attached the logs from when this command was dispatched.
The issue isn’t that an event was skipped; rather, the problem is that all event processors are not handling any events, leading to the application freezing.