My tweak has been to separate the database, using Mongo as the EventStore on the command side and Postgres on the query side.
I have this working but not the way I want. The command side is working fine, EventStore collections are created in Mongo. The trouble is on the query side. Axon is auto-generating the EventStore tables as well as the Entity tables. I don’t need the event store tables because they aren’t used nor need I want auto-generated Entity tables because I’m managing query side tables with Flyway.
I’ve tried adding the following configuration to application.yml but it didn’t make any difference:
spring:
jpa:
generate-ddl: false
hibernate:
hbm2ddl:
auto: none
Any suggestions on how to disable hbm2dll in Axon? Alternatively, is the full Axon Framework really required on the read side? My understanding is that Spring simply needs to read events coming off of a Rabbit queue and persist them.
Since I’m new to this, please point out any ‘errors in thinking’
Axon doesn’t create any tables at all. All Axon does automatically, is register the Entities with the EntityManager (via Spring Boot). It’s you JPA implementation (probably Hibernate) that’s actually generating the tables.
Why setting those values doesn’t have an impact beats me, but it definitely doesn’t relate to Axon at all.
I always set the spring.jpa.hibernate.ddl-auto property myself.
Furthermore, in Spring Boot, DDL is off by default if you are not using an in-memory database.
Whether you need Axon on the query side depends on whether you want to use the @EventHandler mechanism there as well. In Axon 3.1, we will also be introducing the QueryBus. Axon allows you to build your components in such a way, that they are completely oblivious to where they are located in respect to eachother. So whether you deploy them in the same JVM or in different ones, doesn’t change anything (other than a bit of configuration, obviously). Not using Axon on the read side may cause this separation of business and infrastructure to become less obvious.
Thanks for taking the time to respond to my inquiry Allard. Since this is my first foray into microservices and CQRS, perhaps I’m not groking something yet.
The way I’m intending to setup Axon is to have one microservice for updates (create, update, delete) and multiple microservices for reads (general usage api, search engine, messaging, etc). Basically, what is illustrated here: https://docs.axonframework.org/v/3.0/part1/architecture-overview.html in the diagram.
With the Axon Framework jar present on the query side (to be able to use the @EventHandler annotation), and JPA on the classpath, plus Spring and Hibernate auto configuration, the event store and entity tables get auto generated. My understanding is that the event store tables are only needed on the command side. They just sit empty on the query side. Is there any way to tell Axon to not register the Entities with the EntityManager when using it for a query side microservice?
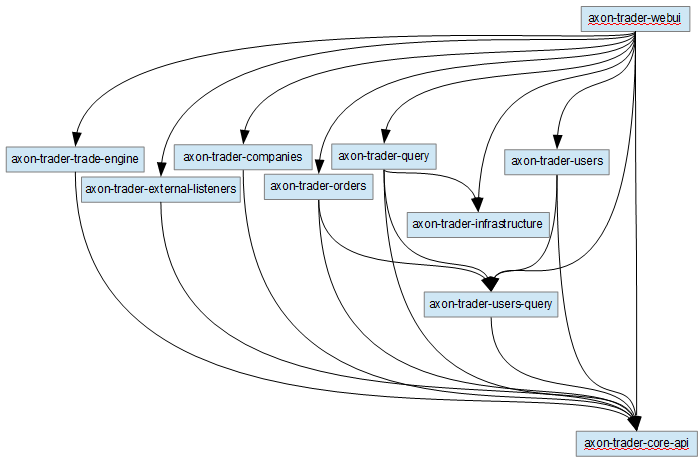
If using an in-memory database (eg. h2, hsql, derby, etc…) then the default value of ddl-auto is create-drop. Otherwise, it’s none. Ideally, you’re going to create tables manually (vs hibernate creating them) or you can use something like flyway/liquibase. Even though the entities will be registered, as long as something doesn’t try to access them, I imagine you should be fine. Since I’m relatively new to this stuff as well, I suggest taking a look at axon trader. I attached a dependency diagram I made to help understand the relationship between each module.
Thanks for responding Brian (and Allard). I’m not using an in-memory database, I’m using Postgres (hosted at elephantsql.com) + Flyway. So my problem is Hibernate, not Axon.
I’ve tried every setting I can find and my tables are still being auto-generated and dropped :`(
don’t know if it’s a copy-paste mistake, but there is no value behind "ddl-auto: ".
It might be interesting to have a setting to prevent Axon registering entities with the EntityManager.
You architecture sounds fine, although we usually recommend not distributing from day one, but doing so when it’s actually necessary.
How are you planning to transport events to your query nodes? You can of course use something like AMQP, but using TrackingProcessors can also read directly from the event store that other components write to. This gives the Event Handlers more influence on which instance of a specific handling node gets which messages. So you can do parallel processing, but still have certain ordering guarantees.
Allard, the blank value was an intentional choice based on a stack overflow thread here and looking at the source here. ‘none’ leaves a WARN in the logs and blank doesn’t (both have the same result).
You are right in that I did choose to distribute the events. I was using this project (and its predecessor) as guides to teach myself about microservices, CQRS and Axon. The way the author fashioned his project was to have separate command and query microservices but share the same (MySQL) database. Everything I’ve read so far suggests that microservices should have their own DB. That’s what motivated me to set up a mongo backed event store on the command side and a postgres DB on the query side, and use Rabbit to connect them. My interpretation of the following architecture diagram led me to think I was on the right path:
I’ll have to get a little further down the road to understand “when it is necessary” to distribute events. It sounds like you have quite a bit of experience (that I don’t have yet) backing up that statement.
If I choose to not distribute the events, doesn’t that result in the the command and query projects living in the same JVM and sharing the same database? This seems like CQRS light to me (less separate), closer to monolithic architecture rather than a microservice architecture where every microservice has their own db. I can see how the command and query code and tables would not be commingled but would live in the same project. Do I have that right?
I come from a monolithic background and this is my first foray into microservices so I’m still fumbling to understand sensible scope and boundaries.
At AxonIQ, we typically suggest to first create a well structured monolith, and partition into smaller micro services as the need arises.
There are several blogs (like this one from Martin Fowler) suggesting this is a better approach do doing micro services the right way.
You might describe it as CQRS light, as you’d indeed have both your Command Model and Query Model in one project and one JVM.
Structuring your project in clear modules separating the command and query model is however a nice starting point here, which should give you the option to scale out later on.
This is not to say that going micro services from the start is wrong, it’s just something we typically do not suggest.
If this project you’re referring to is in the lines of testing/PoC, then I think it’s fine to try it out.
From a production-ready project perspective, I’d say that starting of distributed only adds complexity (and my guess is that’s what Allard would say too).
That’s my 2 cents at least, hope it helps you out a little!
Thanks for the feedback Steven and Allard. You have both helped me navigate to more reasonable starting point. I’m going to heed your advice and head down the well structured monolith path, breaking out microservices as need arises.