Hello
My question is how the segregation of command / write side and query / read side is meant to be implemented.
Because I have found a tutorial series which bifurcates the services into QueryDomainAServiceImpl and CommandDomainAServiceImpl.
On the other hand I have read the book on Microservice Patterns by Richardson and I have read the Axon Documentary Entry on CQRS.
Neither do speak of a bifurcation of services, as far as I can see.
The description of Richardson is similar to the description of CQRS, microservices and event-driven architecture with Axon. | by George | Unil Ci Software Engineering | Medium
Richardson begins at point 7.2 on page 228 of his book to explain the CQRS-Pattern in a comparison to the API composition pattern and both against an example of a “non-trivial query” by the signifier findAvailableRestaurants(). (He already mentions that in Chapter 2) I am unable to make head nor tail out of Richardsons explanation on what exactly his command query segregation looks like. I can at best guess or I’ll have to analyze his code of the example codebase.
It does not, as in the tutorial I found, bifurcate the service in a “CommandDomainServiceImpl” and a “QueryDomainServiceImpl”. Instead he obviously uses two databases per service (?)
The accompagnying diagram of the medium article is also very apt.
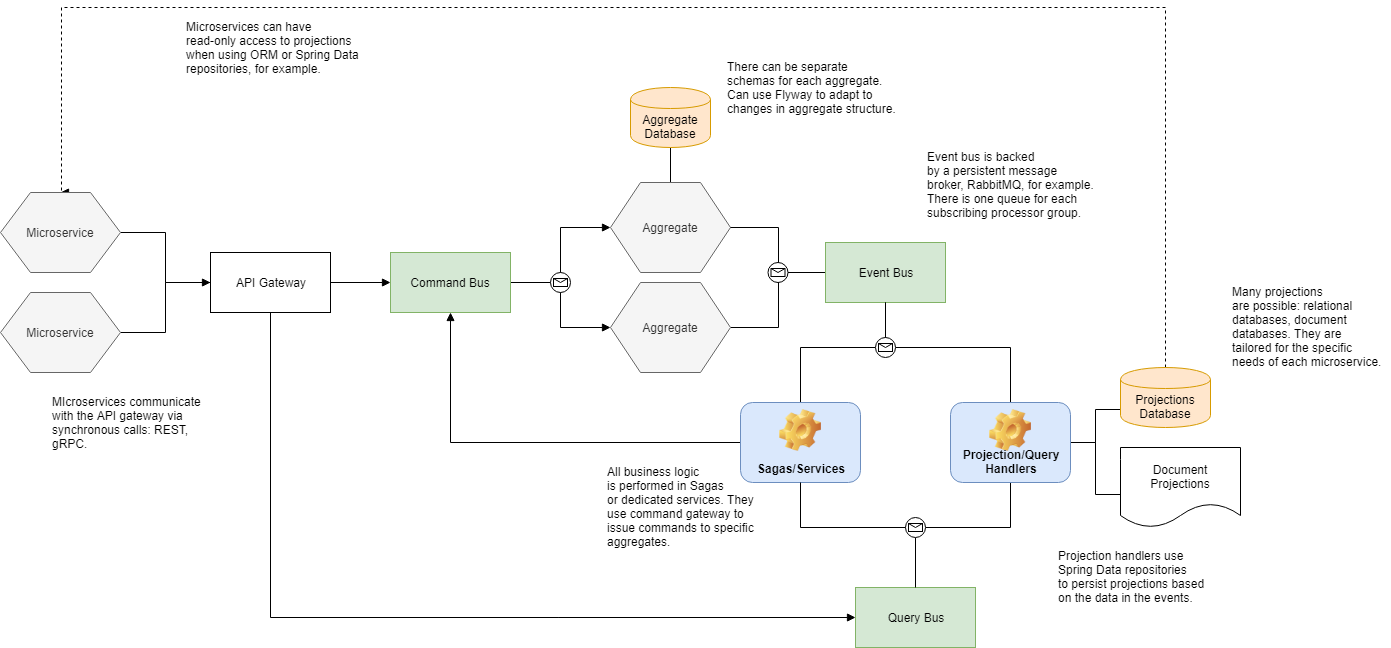
and so is a diagram in a blogpost (The best way to use the Spring Transactional annotation - Vlad Mihalcea) of Vlad Mihalcea to depict read and write side both as replica.
![]()
Richardson goes a similar but slightly different way.
In the most pronounced form the concept of CQRS for Richardson roughly adds up to the Optimistic Replication strategy with Eventual Consistencey consistency model implemented in different standalone read-model services which are each subscribed to the domain events published by all aggregates/services their query model needs. Richardson emphasizes that the read-model-services, he calls them read-modules, are predestined for “non-trivial queries” because each of those “read modules” at minimum rate consists of an own replica data store with data from different services instead of a distributed transaction. Further he says a “read module” can leverage further data stores with special abilities such as geodata to, say, find the next food available food store with a certain dish available for delivery at a certain time. He draws a comparison that traditional services would commit distributed transactions also over additional databases such as Elasticsearch: Die offizielle Engine für verteilte Suche und Analytics | Elastic for text-search (although this database obviously is capable of much more)
He doesn’t yet describe to greater detail how a single service looks then. Each normal domain service in his CQRS interpretation, such as in his diagram on page 233, also has an additional datastore for query transactions. But I don’t know if it is a replica of the first database. I don’t know where the differences are if you use a separate data-store for queries. What does the first data store persist then? He doesn’t really describe it. I would probably have to analyze his “food to go” microservice but I am right now still weakened by a bad fever since two weeks now and I still feel weak.
Would you have a description for me how I should correctly build up my services and read-models in order to correctly realize CQRS ?
I will analyze his Food To Go Store example as soon as I have more power again. But maybe even this won’t lead me a valid/generalizable conclusion, so I think it would be nonetheless not at all be in vain if you could kindly describe to me “the correct way of implementing CQRS.”
What about a separate database for queries for each service? If so, what events do I persist in both databases? Let’s speak of the “write-side” and “read-side” each, both at service level and at application level, where the read-side is some kind of replica and where there are, on application level, possibly multiple replica or at least, “projections” I think it is called when you create a replica but filter events or information you need that you keep vs. events or information that you let drop.
On the data-access level, are this all EventStores ?
And if you would implement standalone services with maybe multiple databases, how would you subscribe to the change-events of multiple services?
Whereas even actually the services would normally not relay the events of AggregateLifecycle#apply to a replica event store. I say normally. How could I configure event handlers and event processors such that some third service would also be informed about change-events it is interested in?
I think I let this post for the time being stand as exposition with some question marks hidden here and there and hope that it develops.
Thank you very much!
Yours sincerely
überSpotz