We are using Axon Server SE event store with Axon Framework. Token store is in JDBC (PostgreSQL). Our distributed application uses CQRS pattern, but we are not using Event Sourcing. Mainly we use the Framework because of great CQRS support and Axon Server because there is no way to use Queries with Kafka or AMPQ extension.
Recently we had couple of incidents in production where Axon Server events volume just got full and this corrupted the store. Even after expanding the volume we could not start Axon Server and had to clear event/token stores. This is not a very big issue, since we are not using Event Sourcing, but we are wondering about the following questions:
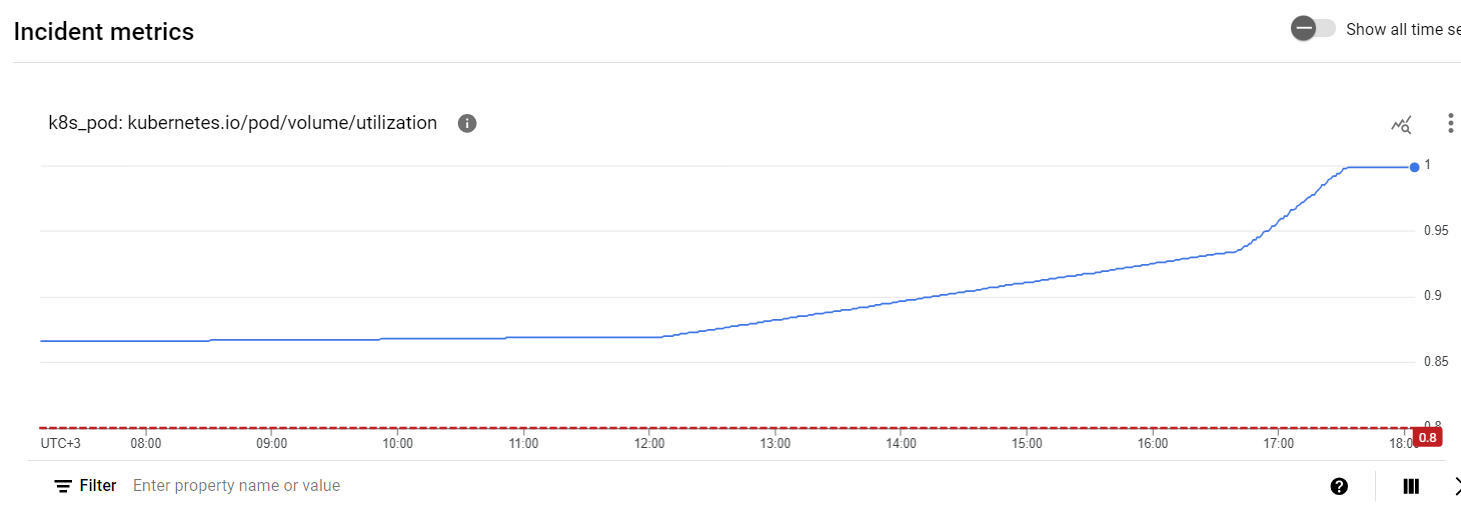
What is the proper way to maintain Axon Server event store volume? Should we run some scheduler script constantly? We already have alerts when the volume gets 80% full, but the issue is that volume space is not infinite even if we expand it multiple times in the future. On top of that, event store usage is not really predictable, see the following volume usage graph, where 15% of disk was used up during just 6 hours:
Is it a good idea to constantly delete old events from the store and if so, is API available for that? Or maybe we need to switch to JDBC event store before doing so?
Are there any mechanics in Framework or the Server itself to protect Event Store from overload, and by doing so, make the disk usage predictable?
Are queries also stored in Event Store? I. e. if we switch events/commands to AMPQ broker and keep only distributed queries on Axon Server will we have the same issue with the volume getting full?
Or maybe we should not be using Axon Server for our use case at all?
Queries are not stored, they are just routed to the destination, the same as commands.
How big is your event store btw?
From version 2024.0.0, (its available before this version but for licensed version only) you can convert your context to ephemeral context, which will automatically delete events after some period of retention size or time.
For example, you can say that max size of event store is 100gb, and when the event store reaches this size, new events will start to push out the oldest event segments, and they will be deleted.
If you enable snapshots, your data will still be accessible if an aggregate needs to load the state, but you will lose the granularity of the events and you will not be able to replay the entire history if needed. If this is acceptable I would say this is the way to go.
Thank you for your reply. Ephemeral context was not known to us so we will definitely look into it.
Are there any known issues with sagas when using ephemeral context? Our sagas are pretty short (couple of days max), but I assume context configuration needs to match what is required from business side regarding sagas length?
Our event store is about 10 GB in size, however we do not have a lot of load at the moment. With our international plans and based on the progress in disk monitoring graphs I assume we could easily reach 1 TB.
when using Ephemeral Contexts, the most important thing to realize is that you’ll lose your history. For the application, as long as it processes events in time (and doesn’t use event sourcing), there will be no impact. Sagas process events and generally update their state in a database.
A little thing about Axon Server. It basically gives you 2 things out of the box.
And Event Store suitable for event sourcing. This is the part that you’re probably not looking to use the full potential. Fortunately, it’s easier to remove events from a system that’s designed to be able to keep them forever, than it is to remember events in a system that’s designed to forget them.
A message router. Axon Server efficiently routes messages based on their stereotype (Commands vs Events vs Queries) and name. Applications register handlers using these names, which gives to complete Location Transparency. This gives you the flexibility to move handlers from one component to another, or scale them independently without having to worry about whether your routing is still correct.
when using Ephemeral Contexts, the most important thing to realize is that you’ll lose your history. For the application, as long as it processes events in time (and doesn’t use event sourcing), there will be no impact.
That is exactly why I’m asking. “In time” is not always achievable.
For example, let’s say we have some longer events in the system which usually take 10-15 minutes. If we for whatever reason will have incident in one of the services, and the events cannot be processed, does this mean that Event Store with Ephemeral Context should be configured, so it keeps events for maximum amount of possible incident time + some time to process them?
I’ve looked at AxonIQ Console when it was introduced but never had time to actually use it. I guess this will change if we opt-in into new server pricing as Console is required then (if I understood it correctly?).
the time to process events is generally measured in seconds. Make that minutes or hours to account for down-time.
The time for ephemeral contexts is generally defined in weeks or months. Some cases even years. If you set it to 10GB, then time is of course variable. How much time would you need to fill up the 10GB?
What I meant to say in my previous message is that it’s not the lifetime of a Saga that counts as the processing time, but rather the processing of a single event, which is orders of magnitude shorter. Hope that makes sense.
Yes, indeed, the new pricing plans are offered through console. So if you want high-availability for Axon Server, Console is the place where you can purchase that. But it also gives you very nice metrics around the behavior of your Axon Framework based applications. The free tier should get you quite far already.
I tried to use ephemeral context with a developer license (server version 2024.0.4). While the context was created successfully, I got the following error in the server log after dispatching the first event:
2024-07-09 07:22:20.456 ERROR 3885617 — [grpc-executor-4] i.a.axonserver.grpc.LicenseInterceptor : Warning: Unauthorized feature(s) that cannot be used with this license have been detected. Please remove them or contact AxonIQ for more information/assistance.
The client application was disconnected with an error:
2024-07-09 07:22:20.549 ERROR [main] org.springframework.boot.SpringApplication : Application run failed
io.grpc.StatusRuntimeException: CANCELLED: License is not valid!