I am looking to migrate a portion of our monolith to Axon because this particular section is rather complex and keeping track of the revisions is desirable. The concept is a Specification. Basically, it consists of lots of data and can be used across various industries such as Food or Chemical suppliers. There are several tabs such as: Shelf Life (how long something will last at various stages of production), Country of Origin, Brand, Credence Claims (eg. Fat Free, Gluten Free, Low Fat, etc…), Certifications (eg. Halal, Kosher, Organic, etc…), Nutrients, Allergens (eg. Eggs, Gluten, Dairy, etc…), Packaging, etc… In short, there are 13 tabs that cover several aspects of a specification. Currently, saving the spec is mostly one big transaction with a few exceptions. History entries are generated, but could not be re-generated if we wanted to enrich the entries or change the format. Editing a spec is really just CRUD, but smaller transactions would be better in addition to an audit trail. When I was fairly new to CQRS/DDD/ES, I was thinking that Specification would be one big aggregate. Now, I’m thinking that it could consist of several smaller aggregates. For example, I’m thinking that I might create a Spec which might then trigger the creation of several other aggregates such as SpecificationNutrients, SpecificationAllergens, etc… and they would all share the same id as the spec. Does this sound like a reasonable approach or am I going about it all wrong?
Hi Brian,
Firstly, regarding your comment on creating several small aggregates that “share the same id,” that is not possible. Each aggregate has a unique @AggregateIdentifier and this Id cannot be used for other aggregates.
Regarding the design of your aggregate(s), there are a few things to consider. Creating an aggregate has to do a lot with the business requirements that you may have at hand. The recommendation is to start with one aggregate and further down the road if you have a large aggregate and the need to de-couple the specifications, then you can break your aggregate into smaller aggregates.
In this scenario that you have explained with the information I have, I suggest that you start with one aggregate, for instance CreateProductSpec, and make the other specs into aggregate members or entities that are tied to this one aggregate. From my understanding, your specs share data and can be left inside of this one aggregate. Keep in mind that each time your aggregates have to communicate with one another you would have to use an orchestrator, such as a Saga or EventHandler. This will add quite a bit of complexity to your design, especially if you have an aggregate that depends on the state of other aggregates.
I am adding a couple of sample concepts based on event modeling created by my colleague @Ivan_Dugalic for your review to see the complexity that can arise from having several aggregates that depend on each other.
Having one aggregate with several aggregate members/entities:
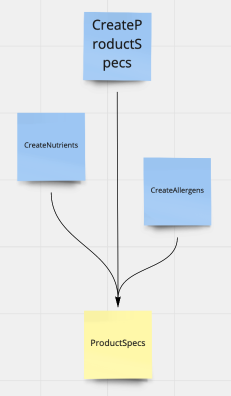
Having several aggregates that communicate using Saga or EventHandler
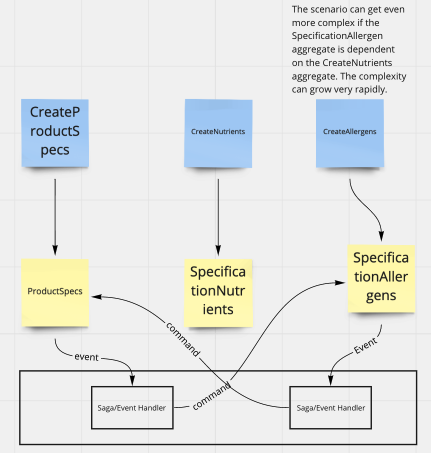
With that in mind, it is of course possible to have many aggregates within a bounded context, and this section of our Reference Guide may be useful for you.
I hope this helps, and I am happy to answer any other questions you may have.
Hello Sara,
Thanks for that response. Ok, so no shared ids. I think each Spec would be its own aggregate at the very least because there are several of them in the system. I imagine that would be a lot of work for the system to replay events for each and every command even if there is a snapshot. My understanding is that an aggregate is more or less a transaction boundary. If 2 people are working on the same spec, but one is doing Nutrients and the other is in Shelf Life, those areas each have their own invariants and are, in essence, independent of each other even though they belong to the same Spec which is why I was thinking of creating an aggregate for each.
For example, on Nutrients, the same name cannot appear more than once.
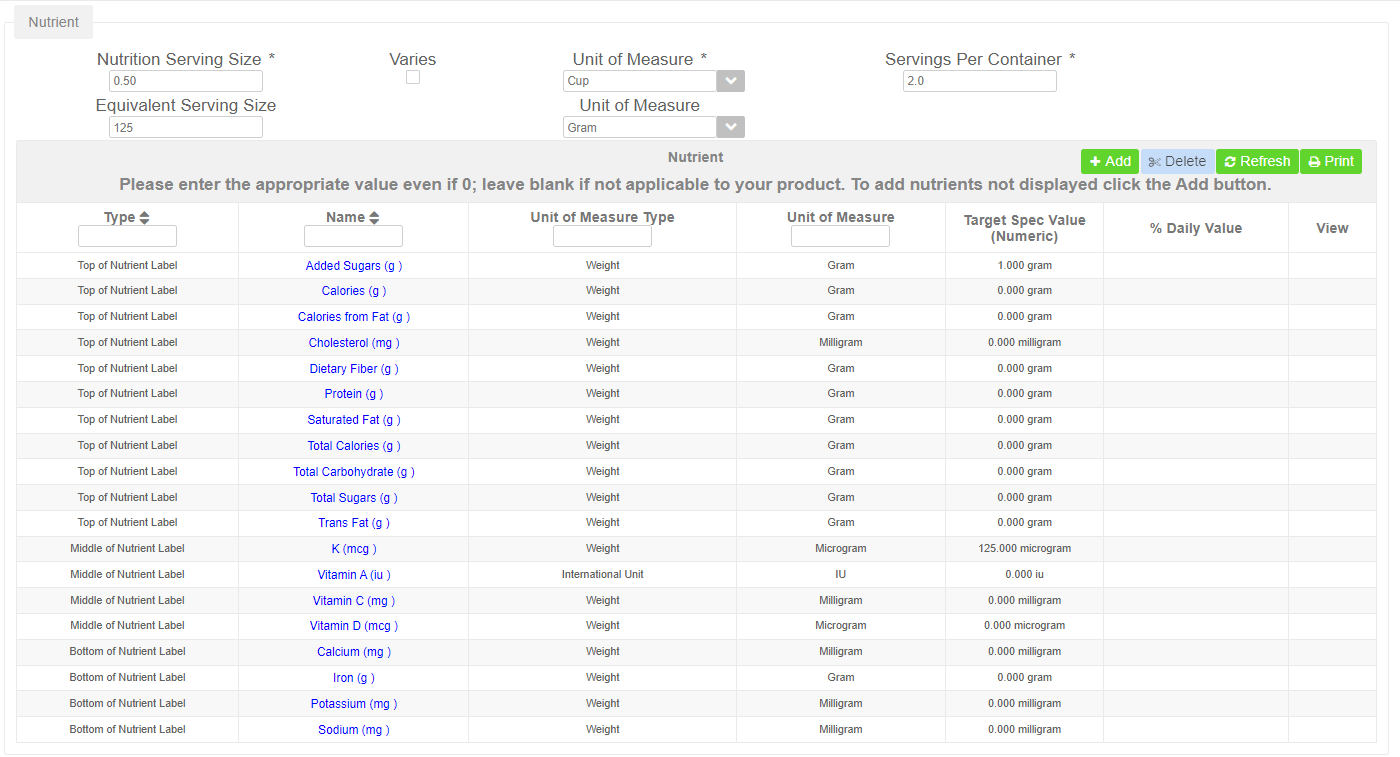
In Shelf Life, Owner/Name must be unique. eg. Total Shelf Life may appear more than once as long as the Owner is different.

Let’s say I did only have one aggregate (eg. Specification) and decided to decompose it a little (eg. SpecificationNutrients, SpecificationShelfLifes), how would that work? My understanding is that changing aggregate boundaries isn’t exactly a small undertaking and is therefore quite important to get right in the beginning. Looking at Axon server, I can see why that might be true because the events that might apply to this new aggregate would still be tied to the old one.
Hi Brian,
Re: “Let’s say I did only have one aggregate (eg. Specification) and decided to decompose it a little (eg. SpecificationNutrients, SpecificationShelfLifes), how would that work?”
If you have a chance to take a look at the Reference Guide, this section (" How to create an Aggregate from another Aggregate") explains how to create a ChildAggregate from a ParentAggregate.
Hopefully, that helps.
Hello Sara,
I was actually looking at that section earlier today  The impression I get is that it is more applicable if you are doing it from the beginning since the call is done from the CommandHandler. Let’s say that I did only have Specification as the aggregate and there are Shelf Life/Nutrient events tied to this aggregate and then sometime down the road I decide that I wanted to break each section into its own aggregate, shouldn’t the event instead go to the new aggregate?
The impression I get is that it is more applicable if you are doing it from the beginning since the call is done from the CommandHandler. Let’s say that I did only have Specification as the aggregate and there are Shelf Life/Nutrient events tied to this aggregate and then sometime down the road I decide that I wanted to break each section into its own aggregate, shouldn’t the event instead go to the new aggregate?
Hi Brian,
In this case, one real solution might be a use-once custom tool to change the aggregate Ids in the event store or re-publish the events to a new event store/context with the correct ids. This scenario would require a rewrite of the event stream so that the events can be re-linked to their new “owner.”
Hi Brian,
let me add my two cents to the discussion as we faced similar issue a few months ago. Three alternatives came up:
(1) a single aggregate class - I would not recommend this approach in your situation.
(2) an aggregate class with member classes - This allows you to split parts and responsibilities of the Specification aggregate (in DDD terms) across multiple fine tuned classes with the advantage of having only one ID.
(3) multiple aggregate classes - This approach allows you to extend functionality of your main aggregate (the Specification) quite easily. As I see it, all specifications share a few basic attributes, such as a name. Each extension is then its own aggregate class with its own ID but references the main Specification aggregate. Nice feature here is that you can develop and deploy each extension as a microservice independently. However the data model becomes a bit complex due to having two identifiers - one for the specification and another for the extension.
HTH,
David