Hi,
I’m experiencing some strange behavior with AxonServer 4.0.2 and 4.0.3 on Kubernetes
(I’m using the official Docker image from https://hub.docker.com/r/axoniq/axonserver/ )
- so far the 4.0 version has been working without any issues.
When switching to 4.0.3 (also tried 4.0.2) I started to experience out of memory errors
from AxonServer:
Exception in thread “event-stream-1” io.netty.util.internal.OutOfDirectMemoryError: failed to allocate 16777216 byte(s) of direct memory (used: 469762327, max: 477626368) at io.netty.util.internal.PlatformDependent.incrementMemoryCounter
io.netty.util.internal.OutOfDirectMemoryError: failed to allocate 16777216 byte(s) of direct memory (used: 469762327, max: 477626368) at io.netty.util.internal.PlatformDependent.incrementMemoryCounter
I noticed the startup script in the official image has a hardcoded -Xmx512m memory setting:
https://github.com/AxonIQ/axon-server-dockerfile/blob/master/src/main/docker/startup.sh
I guess it should be configurable - it doesn’t appear to be sufficient for the newer versions. Anyway, I built a custom image,
raised the memory limit, out of memory went away, but then I’ve noticed another thing.
This occurs during replay:
“Connecting to AxonServer node axonserver:8124 failed: UNAVAILABLE: Unable to resolve host axonserver”
[io.grpc.internal.ManagedChannelImpl-16] Failed to resolve name. status=Status{code=UNAVAILABLE, description=Unable to resolve host axonserver, cause=java.net.UnknownHostException: axonserver at java.net.InetAddress.getAllByName0(InetAddress.java:1281) at java.net.InetAddress.getAllByName(InetAddress.java:1193) at java.net.InetAddress.getAllByName(InetAddress.java:1127) at io.grpc.internal.DnsNameResolver$JdkResolver.resolve(DnsNameResolver.java:497) at io.grpc.internal.DnsNameResolver$1.run(DnsNameResolver.java:200) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) }
(only a couple of times, and then it can reconnect)
I’ve got zero clues why this pops up, nothing has changed except for the axonserver version upgrade 4.0 -> 4.0.3.
I’ve never had such an issue with 4.0.
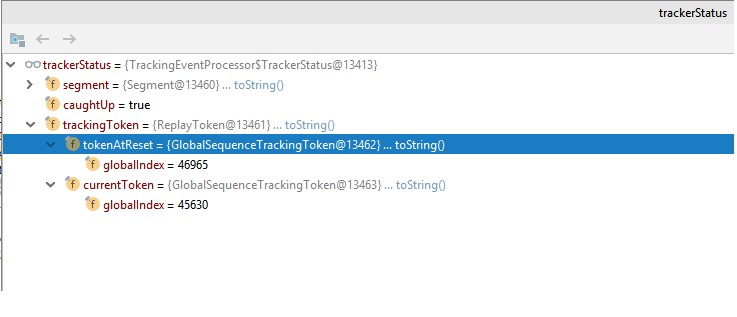
Also what I see, after replay, when I check the indexes of replayToken.getTokenAtReset() and replayToken.getCurrentToken(),
even after the replay finished and the event processor is caught up, currentToken’s global index remains at 46946
although tokenAtReset’s global index is 46962… it should have the same index, means replayed all of the events, right?
It has always been like that so far, what does this mean? Not everything is replayed?
I can’t see any eventprocessing errors though (in the logs of my projections) or any other exceptions for that matter… only
the ‘Unable to resolve host axonserver’ errors.
These problems only occur on GKE … running on my local machine it looks fine.
Is there something that has changed since 4.0 and I might have overlooked?
Meanwhile I reverted back to 4.0, things are back to normal, zero issues.
Thanks,
Regards